
Introducing Mesa

Sep 24, 2025
Much has been written on The Death of Software Engineering™️ but if you’re a SWE working in a professional setting you’re experiencing more work than ever. AI-driven development is allowing engineers to churn out tens of thousands of lines of a code a week but software engineering doesn’t begin and end in the IDE.
SWEs do more than just write code, they build systems, and as the velocity of code authoring continues to go exponential the ability to effectively review and verify changes to the system is becoming more important than ever.
The Changing Pace of Software Development
Developing software is hard. The majority of software projects are delivered over budget and behind schedule, if they’re delivered at all. This difficulty costs companies and the government hundreds of billions of dollars annually.
It’s no wonder everyone is trying to find and fix the bottlenecks in software development.

The chart above is one I continuously reference when explaining the importance of Mesa. So much recent progress with AI-driven development focuses on writing software — with great success — but this only moves the bottleneck in the development process.
Engineering teams on the cutting edge of AI-driven development are seeing this happen already. These teams are watching in realtime how the bottleneck on development velocity move from writing code to reviewing it.
Individual engineers are writing 10x as much code as before and now engineers are faced with a choice: spend all your time reviewing code or don’t review the code at all and just give rubber stamps. Without a revolution in the way we verify changes we won't be any more productive building software.
In an enterprise setting, every line of code needs to be verified with manual review, testing, and QA. In recent decades companies have moved away from dedicated QA teams to a model where each software engineer reviews the code of their teammates. This saved on cost and allowed teams to move faster but this model is breaking.
You can avoid reviewing the code which will remove this bottleneck but that significantly raises the risk of shipping bugs that can cause outages, security breaches, and broken products that reduce customer trust. And it then you still need to spend expensive engineering time doing root-cause-analysis and fixing the mistakes that were shipped.
Code review is not the place to kick the bottleneck down the road.
Naturally, the instinct is to reach for code review agents, oftentimes starting with Copilot because it’s built into GitHub, but then experimenting with CodeRabbit, Graphite, and Claude Code.
The reaction to these review agents is universal:
Wow, these agents are preventing multiple serious bugs per week
Ugh, these agents are nitpicking and missing pretty critical problems with our larger system
It’s understandable. These models are smart and they catch real bugs but they suffer from tunnel vision. They sometimes struggle to tell the forest from the trees.
That’s where Mesa comes in.
Mesa’s Context-Aware Reviews
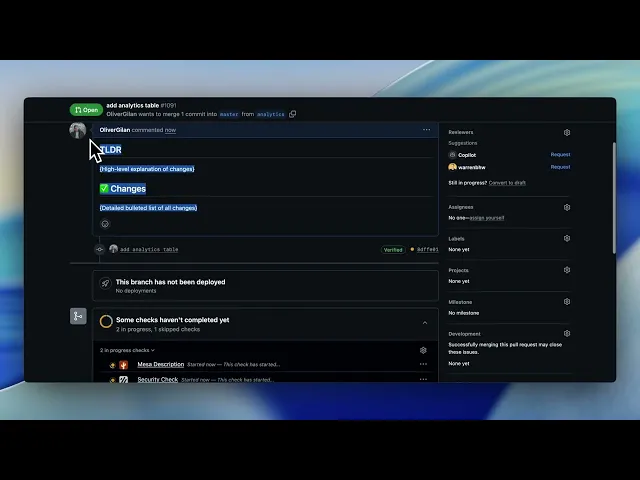
Mesa is a code review agent that sees beyond just the PR itself. It has full access to your codebase, can follow links to research dependencies, and soon will be able to natively pull from your task management tool, Slack, and other tools containing critical context of your pull request. This makes Mesa better than any other tool at catching bugs and mistakes, not just in the PR diff itself, but in surrounding code that is affected by the changes.

Take this instance for example, where I bumped our Node version in our deployment image. The only changed file in the PR was this specific Dockerfile but our agent correctly identified inconsistencies in the untouched package.json for that specific service as well as inconsistencies in adjacent services such as our Admin dashboard.
Other review agents would see this code as being fine because at face value, there’s no bug in the PR diff itself. Only when taken in the context of the larger project does it become clear something is wrong.
Multi-Agent Reviews
We strengthen the context awareness of our reviewer through the use of a multi-agent review system. With Mesa, you define custom agents that specialize in a specific dimension of your codebase that you care about. This can be as general as a Frontend or Backend agent, or as specific as targeting a specific dependency.

In our own codebase we have specific expert agents for Drizzle and Zero, two libraries we use for interacting with our database and syncing realtime data to our frontend. These libraries are complex and, for Zero especially, newer. It’s incredibly important that we do not misuse them and accidentally introduce performance issues or data integrity bugs.
By creating custom agents, we can craft specific prompts, rulesets, and even customize the foundation model used to evaluate code changes that touch these elements of our codebase. When a review is run our orchestrator agent intelligently delegates different parts of the review to various custom agents and then aggregates the results into a final review. This allows us to tailor the reviews to look for the exact issues we care about across our codebase and reduce noise in the reviews.
Beyond customizing what the review looks for, we can also customize how it does the review through changing the model. We set our Security agent to use GPT-5-high with maximum thinking budget because we want to spend as much time and tokens as possible to ensure we’re not making a mistake there. On the other hand, in our Frontend agent can use Claude-4-sonnet because it’s lower stakes and we’d rather optimize speed and cost.
Whereas other review agents focus on the micro and come one-size-fits-all, Mesa is designed to understand all the various dimensions of your codebase and flex it’s reasoning up and down to meet your needs.
Mesa’s Public Beta
We are now in public beta and the product is generally available for people to use. You can sign up and try the product for free or put in your credit card to access the best models like 4.1 Opus and pay for only the tokens you use (at-cost).
Over the coming weeks we’ll ship improvements to let you automatically generate agents from historical reviews and your existing codebase, improve your custom agents over time automatically, and select even more models. We’re also working on the most comprehensive open source evaluation set for review agents which we’ll be releasing soon.
If you try out Mesa, do not hesitate to give us feedback on X and join our Discord server!


Navigation
Join the community
Resources
© 2025 Mesa. All rights reserved.
All Systems Operational